Warning
This page was created from a pull request (#326).
Running your first calculation¶
In this section we’ll be learning how to run external codes with AiiDA through calculation plugins.
We will use the Quantum ESPRESSO package to launch a simple density functional theory calculation of a silicon crystal using the PBE exchange-correlation functional and check its results.
Note that besides the aiida-quantumespresso plugin, AiiDA comes with plugins for many other codes, all of which are listed in the AiiDA plugin registry.
The provenance graph¶
Fig. 5 shows a typical example of a Quantum ESPRESSO calculation represented in an AiiDA graph. Have a look to the figure and its caption before moving on.
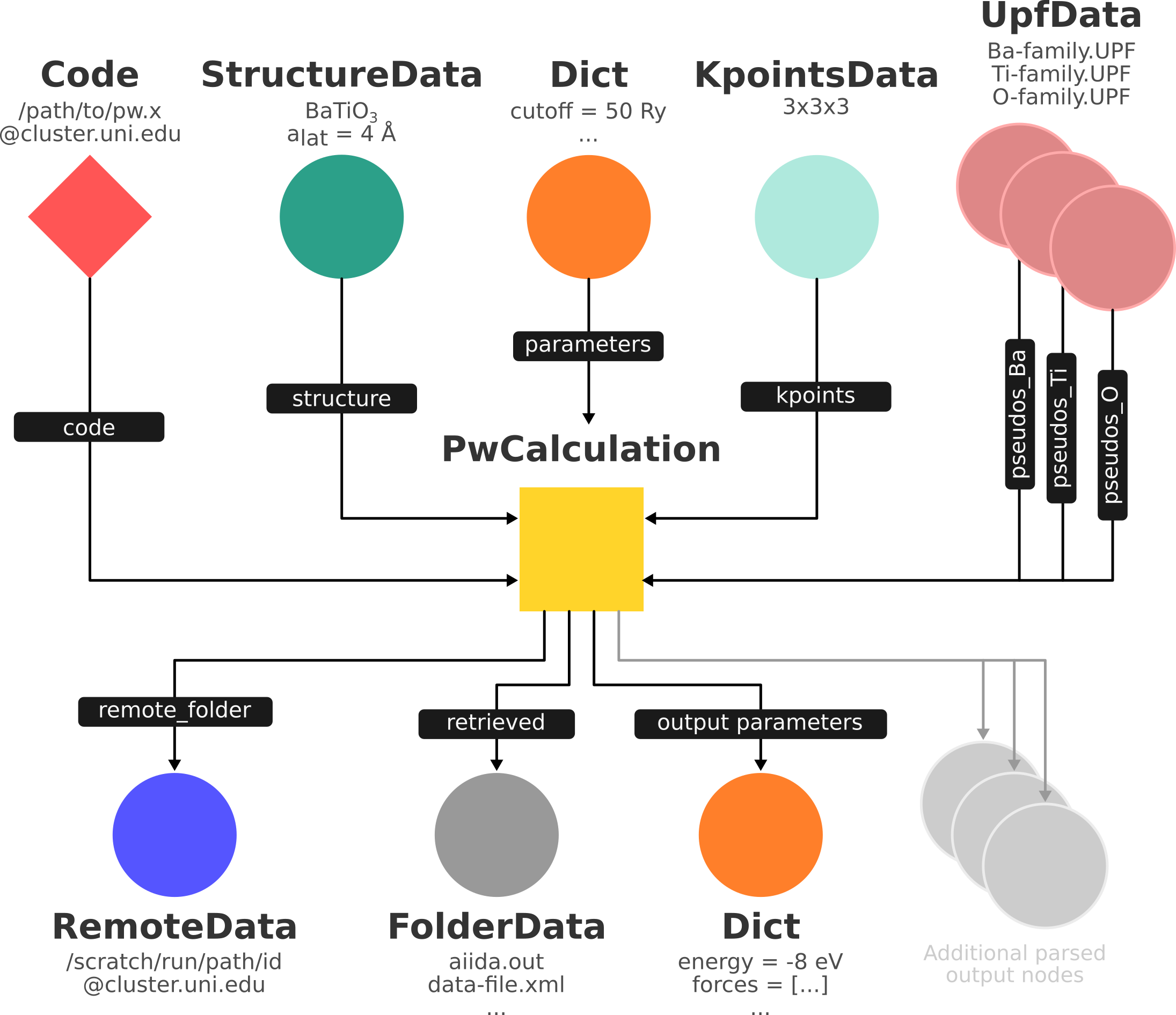
Fig. 5 Graph with all inputs (data, circles; and code, diamond) to the Quantum ESPRESSO calculation (square) that you will create in this module.
Besides the inputs, the graph also shows the outputs that the engine will create and connect automatically.
The RemoteData node is created during submission and can be thought as a symbolic link to the remote folder in which the calculation runs on the cluster.
The other nodes are created when the calculation has finished, after retrieval and parsing.
The node with linkname retrieved contains the relevant raw output files stored in the AiiDA repository; all other nodes are added by the parser.
Additional nodes (symbolized in gray) can be added by the parser: e.g., an output StructureData if you performed a relaxation calculation, a TrajectoryData for molecular dynamics, etc.¶
Fig. 5 was drawn by hand but you can generate a similar graph automatically by passing the identifier of a calculation node to verdi node graph generate <IDENTIFIER>, or using the graph’s python API.
Remember that identifiers in AiiDA can come in several forms:
“Primary Key” (PK): An integer, e.g.
723, that identifies your entity within your database (automatically assigned)Universally Unique Identifier (UUID): A string, e.g.
ce81c420-7751-48f6-af8e-eb7c6a30cec3that identifies your entity globally (automatically assigned)Label: A human-readable string, e.g.
test_qe_calculation(manually assigned)
Any verdi command that expects an identifier will accept a PK, a UUID or a label (although not all entities have a label by default).
While PKs are often shorter than UUIDs and can be easier to remember, they are only unique within your database.
Whenever you intend to share your data with others, use UUIDs to refer to nodes.
Note
For UUIDs, it is sufficient to specify a subset (starting at the beginning) as long as it can already be uniquely resolved.
For more information on identifiers in verdi and AiiDA in general, see the documentation.
Importing a structure and inspecting it¶
First, download the Si structure file: Si.cif.
You can download the file easily using wget:
$ wget https://aiida-tutorials.readthedocs.io/en/tutorial-2021-abc/_downloads/1383def58ffe702e2911585fea20e33d/Si.cif
Note
You may have noticed that on the top right of each code block there a button for copying the contents of the block. This nifty feature will only copy the commands that needs to be executed, but note that in some code snippets you might still have to replace some of the content! On the AiiDAlab cluster you will be able to use the usual short-key of your operating system to paste the contents (Ctrl+V or Command+V), but in the terminal of the Quantum Mobile machine you will need to add Shift (Shift+Ctrl+V).
Next, you can import it into your database with the verdi CLI.
$ verdi data structure import ase Si.cif
Successfully imported structure Si2 (PK = 1)
Each piece of data in AiiDA gets a PK number (a “primary key”) that identifies it in your database.
This is printed out on the screen by the verdi data structure import command.
It’s a good idea to mark it down, but should you forget, you can always have a look at the structures in the database using:
$ verdi data structure list
Id Label Formula
---- ------- ---------
1 Si2
The first column (marked Id) are the PK’s of the StructureData nodes.
Important
If you are starting this tutorial with an empty database, as in this example, the Si structure node PK will also be 1.
If not, the PK numbers shown throughout this tutorial will be different for your database!
Throughout this section, replace the string <PK> with the appropriate PK number.
Let us first inspect the node you just created:
$ verdi node show <PK>
Property Value
----------- ------------------------------------
type StructureData
pk 1
uuid ddb8c21c-2d3f-4374-aa86-44f8bb84aa3f
label
description
ctime 2021-02-09 20:57:03.304174+00:00
mtime 2021-02-09 20:57:03.421210+00:00
You can see some information on the node, including its type (StructureData, the AiiDA data type for storing crystal structures), a label and a description (empty for now, can be changed), a creation time (ctime) and a last modification time (mtime), the PK of the node and its UUID (universally unique identifier).
The PK and UUID both reference the node with the only difference that the PK is unique for your local database only, whereas the UUID is a globally unique identifier and can therefore be used between different databases.
Important
The UUIDs are generated randomly and are therefore guaranteed to be different from the ones shown here.
In the commands that follow, remember to replace <PK>, or <UUID> by the appropriate identifier.
Running a calculation¶
We’ll start with running a simple self-consistent field calculation (SCF) with Quantum ESPRESSO for the structure we just imported. First, we’ll need to make sure we have set up the Quantum ESPRESSO code in our database. This will depend on whether you are running the tutorial in the Quantum Mobile or the AiiDAlab cluster:
Let’s have a look at the codes in our database with the verdi shell:
$ verdi code list
# List of configured codes:
# (use 'verdi code show CODEID' to see the details)
* pk 1 - qe-3.4.0-pw@localhost
* pk 2 - qe-3.4.0-cp@localhost
* pk 3 - qe-3.4.0-pp@localhost
* pk 4 - qe-3.4.0-ph@localhost
* pk 5 - qe-3.4.0-neb@localhost
* pk 6 - qe-3.4.0-projwfc@localhost
* pk 7 - qe-3.4.0-pw2wannier90@localhost
* pk 8 - qe-3.4.0-q2r@localhost
* pk 9 - qe-3.4.0-dos@localhost
* pk 10 - qe-3.4.0-matdyn@localhost
As you can see, this Quantum Mobile virtual machine already comes with all of the Quantum ESPRESSO codes set up in the AiiDA database.
The code we will be running is the pw.x code, set up under the label qe-3.4.0-pw on the localhost computer.
Make a note of the PK or label of the code, since you’ll need to replace it in code snippets later in this tutorial.
Let’s have a look at the codes in our database with the verdi shell:
$ verdi code list
# List of configured codes:
# (use 'verdi code show CODEID' to see the details)
# No codes found matching the specified criteria.
We can see that no code has been installed yet.
To install the Quantum ESPRESSO pw.x code, we can use the following verdi CLI command:
$ verdi code setup --label pw --computer localhost --remote-abs-path /usr/bin/pw.x --input-plugin quantumespresso.pw --non-interactive
Success: Code<2> pw@localhost created
You now should see the code we have just set up when you execute verdi code list:
$ verdi code list
# List of configured codes:
# (use 'verdi code show CODEID' to see the details)
* pk 2 - pw@localhost
Make a note of the PK or label of the code, since you’ll need to replace it in code snippets later in this tutorial.
To run the SCF calculation, we’ll also need to provide the family of pseudopotentials.
These can be installed easily using the aiida-pseudo package:
$ aiida-pseudo install sssp
Info: downloading selected pseudo potentials archive... [OK]
Info: downloading selected pseudo potentials metadata... [OK]
Info: unpacking archive and parsing pseudos... [OK]
Success: installed `SSSP/1.1/PBE/efficiency` containing 85 pseudo potentials
This command will install the SSSP library version 1.1. To see if the pseudopotential families have been installed correctly, do:
$ aiida-pseudo list
Label Type string Count
----------------------- ------------------ -------
SSSP/1.1/PBE/efficiency pseudo.family.sssp 85
Along with the PK of the StructureData node for the silicon structure that we imported in the previous section, we now have everything to set up the calculation step by step.
Before doing so we will first shut down the AiiDA daemon.
The daemon is a program that runs in the background and manages submitted calculations until they are terminated.
Check the status of the daemon using the verdi CLI:
$ verdi daemon status
If the daemon is running, the output will be something like the following:
Profile: default
Daemon is running as PID 1033 since 2020-11-29 14:37:59
Active workers [1]:
PID MEM % CPU % started
----- ------- ------- -------------------
1036 0.415 0 2020-11-29 14:38:00
In this case, let’s stop it for now:
$ verdi daemon stop
Profile: default
Waiting for the daemon to shut down... OK
We will set up the calculation in the verdi shell, an interactive IPython shell that has many basic AiiDA classes pre-loaded.
To start the IPython shell, simply type in the terminal:
$ verdi shell
First, we’ll load the code from the database using its PK:
In [1]: code = load_code(<CODE_PK>)
Be sure to replace <CODE_PK> with the primary key of the pw.x code in your database!
Every code has a convenient tool for setting up the required input, called the builder.
It can be obtained by using the get_builder method:
In [2]: builder = code.get_builder()
Let’s supply the builder with the structure we just imported.
Replace the <STRUCTURE_PK> with that of the structure we imported at the start of the section:
In [3]: structure = load_node(<STRUCTURE_PK>)
...: builder.structure = structure
Note
One nifty feature of the builder is the ability to use tab completion for the inputs.
Try it out by typing builder. + <TAB> in the verdi shell.
You can get more information on an input by adding a question mark ?:
In [4]: builder.structure?
Type: property
String form: <property object at 0x7f3393e81050>
Docstring: {"name": "structure", "required": "True", "valid_type": "<class 'aiida.orm.nodes.data.structure.StructureData'>", "help": "The input structure.", "non_db": "False"}
Here you can see that the structure input is required, needs to be of the StructureData type and is stored in the database ("non_db": "False").
Next, we’ll need a dictionary that maps the elements to the pseudopotentials we want to use.
Let’s first load the pseudopotential family we installed before with aiida-pseudo:
In [5]: pseudo_family = load_group('SSSP/1.1/PBE/efficiency')
Note
Notice how we use the load_group command here.
An AiiDA Group is a convenient way of organizing your data.
We’ll see more on how to use groups in the section on Working with data.
The required pseudos for any structure can be easily obtained using the get_pseudos() method of the pseudo_family:
In [6]: pseudos = pseudo_family.get_pseudos(structure=structure)
If we check the contents of the pseudos variable:
In [6]: pseudos
Out[6]: {'Si': <UpfData: uuid: afa12680-efd3-4e9a-b4a7-b7a69ee2da51 (pk: 69)>}
We can see that it is a simple dictionary that maps the 'Si' element to a UpfData node, which contains the pseudopotential for silicon in the database.
Let’s pass the pseudos to the builder:
In [7]: builder.pseudos = pseudos
Of course, we also have to set some computational parameters. We’ll first set up a dictionary with a simple set of input parameters for Quantum ESPRESSO:
In [8]: parameters = {
...: 'CONTROL': {
...: 'calculation': 'scf', # self-consistent field
...: },
...: 'SYSTEM': {
...: 'ecutwfc': 30., # wave function cutoff in Ry
...: 'ecutrho': 240., # density cutoff in Ry
...: },
...: }
In order to store them in the database, they must be passed to the builder as a Dict node:
In [9]: builder.parameters = Dict(dict=parameters)
The k-points mesh can be supplied via a KpointsData node.
Load the corresponding class using the DataFactory:
In [10]: KpointsData = DataFactory('array.kpoints')
The DataFactory is a useful and robust tool for loading data types based on their entry point, e.g. 'array.kpoints' in this case.
Once the class is loaded, defining the k-points mesh and passing it to the builder is easy:
In [11]: kpoints = KpointsData()
...: kpoints.set_kpoints_mesh([4,4,4])
...: builder.kpoints = kpoints
Finally, we can also specify the resources we want to use for our calculation. These are stored in the metadata:
In [12]: builder.metadata.options.resources = {'num_machines': 1}
Great, we’re all set! Now all that is left to do is to submit the builder to the daemon.
In [13]: from aiida.engine import submit
...: calcjob_node = submit(builder)
Let’s exit the verdi shell using the exit() command and check the list of processes stored in your database with verdi process list:
$ verdi process list
PK Created Process label Process State Process status
---- --------- --------------- --------------- ----------------
90 36s ago PwCalculation ⏹ Created
Total results: 1
Info: last time an entry changed state: 36s ago (at 23:14:25 on 2021-02-09)
Warning: the daemon is not running
We can see the PwCalculation we have just set up, i.e. the process that runs a Quantum ESPRESSO pw.x calculation.
It’s currently in the Created state.
In order to run the calculation, we have to start the daemon:
$ verdi daemon start
From this point onwards, the AiiDA daemon will take care of your calculation: creating the necessary input files, running the calculation, and parsing its results. The calculation should take less than one minute to complete.
Analyzing the outputs of a calculation¶
Let’s have a look how your calculation is doing!
By default verdi process list only shows the active processes.
To see all processes, use the --all option:
$ verdi process list --all
PK Created Process label Process State Process status
---- --------- --------------- --------------- ----------------
90 8m ago PwCalculation ⏹ Finished [0]
Total results: 1
Info: last time an entry changed state: 22s ago (at 23:22:07 on 2021-02-09)
Use the PK of the PwCalculation to get more information on it:
$ verdi process show <PK>
Property Value
----------- ------------------------------------
type PwCalculation
state Finished [0]
pk 90
uuid 85e38ed3-bb42-4a4b-bd28-d8031736193e
label
description
ctime 2021-02-09 23:14:24.899458+00:00
mtime 2021-02-09 23:22:07.100611+00:00
computer [1] localhost
Inputs PK Type
---------- ---- -------------
pseudos
Si 69 UpfData
code 2 Code
kpoints 89 KpointsData
parameters 88 Dict
structure 1 StructureData
Outputs PK Type
----------------- ---- --------------
output_band 93 BandsData
output_parameters 95 Dict
output_trajectory 94 TrajectoryData
remote_folder 91 RemoteData
retrieved 92 FolderData
As you can see, AiiDA has tracked all the inputs provided to the calculation, allowing you (or anyone else) to reproduce it later on. AiiDA’s record of a calculation is best displayed in the form of a provenance graph:
Fig. 6 Provenance graph for a single Quantum ESPRESSO calculation.¶
To reproduce the figure using the PK of your calculation, you can use the following verdi command:
$ verdi node graph generate <PK>
The command will write the provenance graph to a .pdf file.
How you can open this file will depend on the platform you are running the tutorial on:
You can simply use the evince command to open the .pdf that contains the provenance graph:
$ evince <PK>.dot.pdf
If you open a file manager on the starting page of the AiiDA JupyterHub:

You should be able to use the file manager to navigate to and open the PDF.
Let’s have a look at one of the outputs, i.e. the output_parameters.
You can get the contents of this dictionary easily using the verdi shell:
In [1]: node = load_node(<PK>)
...: d = node.get_dict()
...: d['energy']
Out[1]: -310.56907438957
Moreover, you can also easily access the input and output files of the calculation using the verdi CLI:
$ verdi calcjob inputls <PK> # Shows the list of input files
$ verdi calcjob inputcat <PK> # Shows the input file of the calculation
$ verdi calcjob outputls <PK> # Shows the list of output files
$ verdi calcjob outputcat <PK> # Shows the output file of the calculation
$ verdi calcjob res <PK> # Shows the parser results of the calculation
Exercise: A few questions you could answer using these commands (optional):
How many atoms did the structure contain? How many electrons?
How many k-points were specified? How many k-points were actually computed? Why?
How many SCF iterations were needed for convergence?
How long did Quantum ESPRESSO actually run (wall time)?